sad-indigo
Broken knowledge base
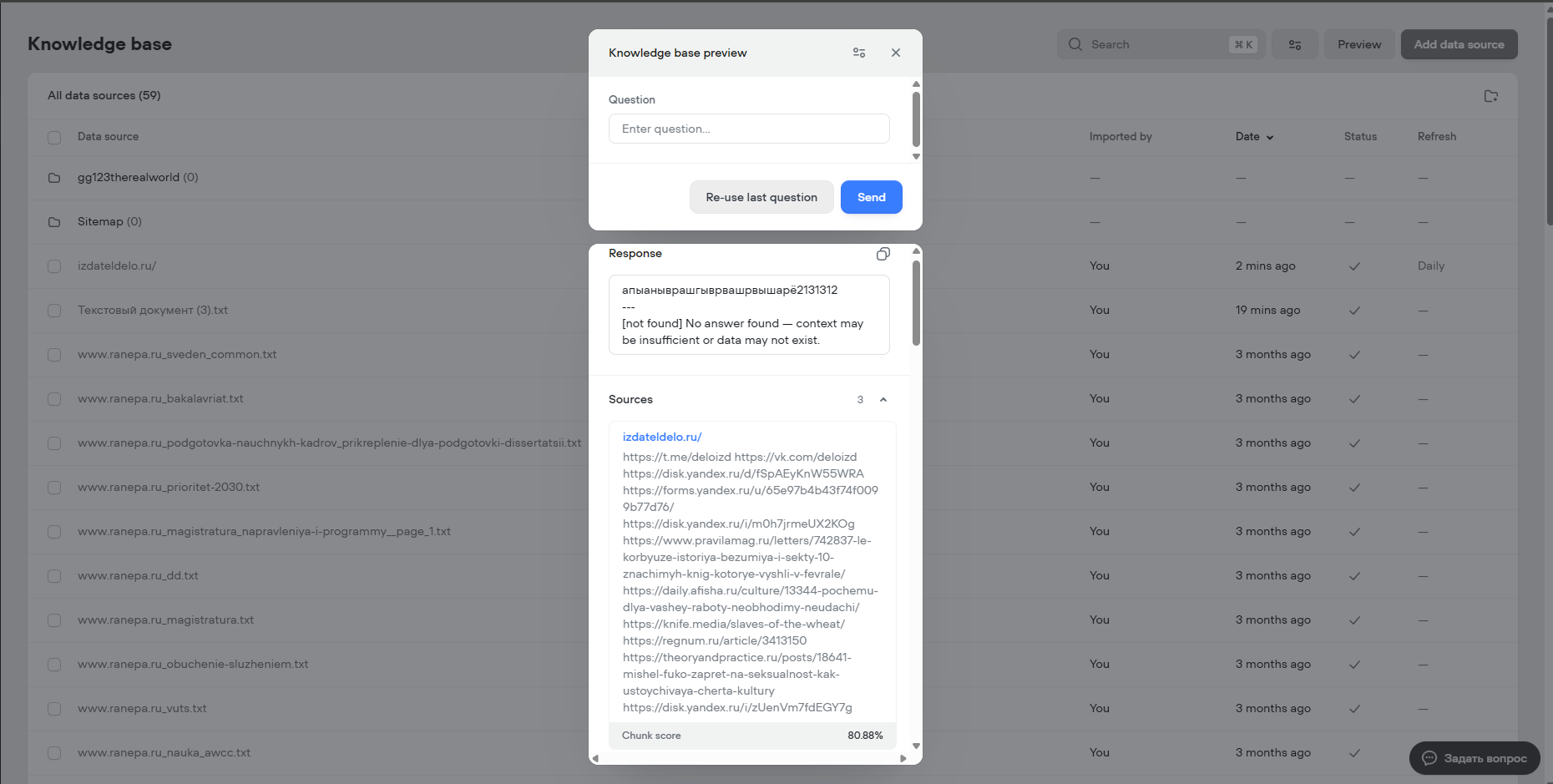
My project's knowledge base is broken. Whatever I enter in the search, even if it's just a set of letters, it shows a chunk score of 80+%. Not only does it give such high percentages, it also searches by one link and does not take into account my text files that are in the knowledge base.
When I delete the only URL, it does not find any chunks at all when searching by the rest of the data.
For clarity, I created another project with the same knowledge base and there the same query, consisting of a set of letters, gives 15-30% relevance, not 80+.
Because of this error, my knowledge base search cannot find normal chunks to answer the question, everything broke for me because of this.
I had the same problem 4 months ago in another project. Then the knowledge base only had URLs, and each search also gave 80+ relevance. Changing the model, resetting the settings and changing the model prompt did not help me. The only thing that helped me was resynchronizing all the data with the YURL.
But in this project I can't do that, because I mostly have files, not links. And it's very strange that this is happening, I would like you to pay attention, since you apparently don't know about it.
KB search behaves the same way.
I would not want to go and delete my entire knowledge base and add it again now, I'm sure that this problem will also happen in the future, it would be better if you fixed it, or told me what the problem is and how I can solve it in the best way.
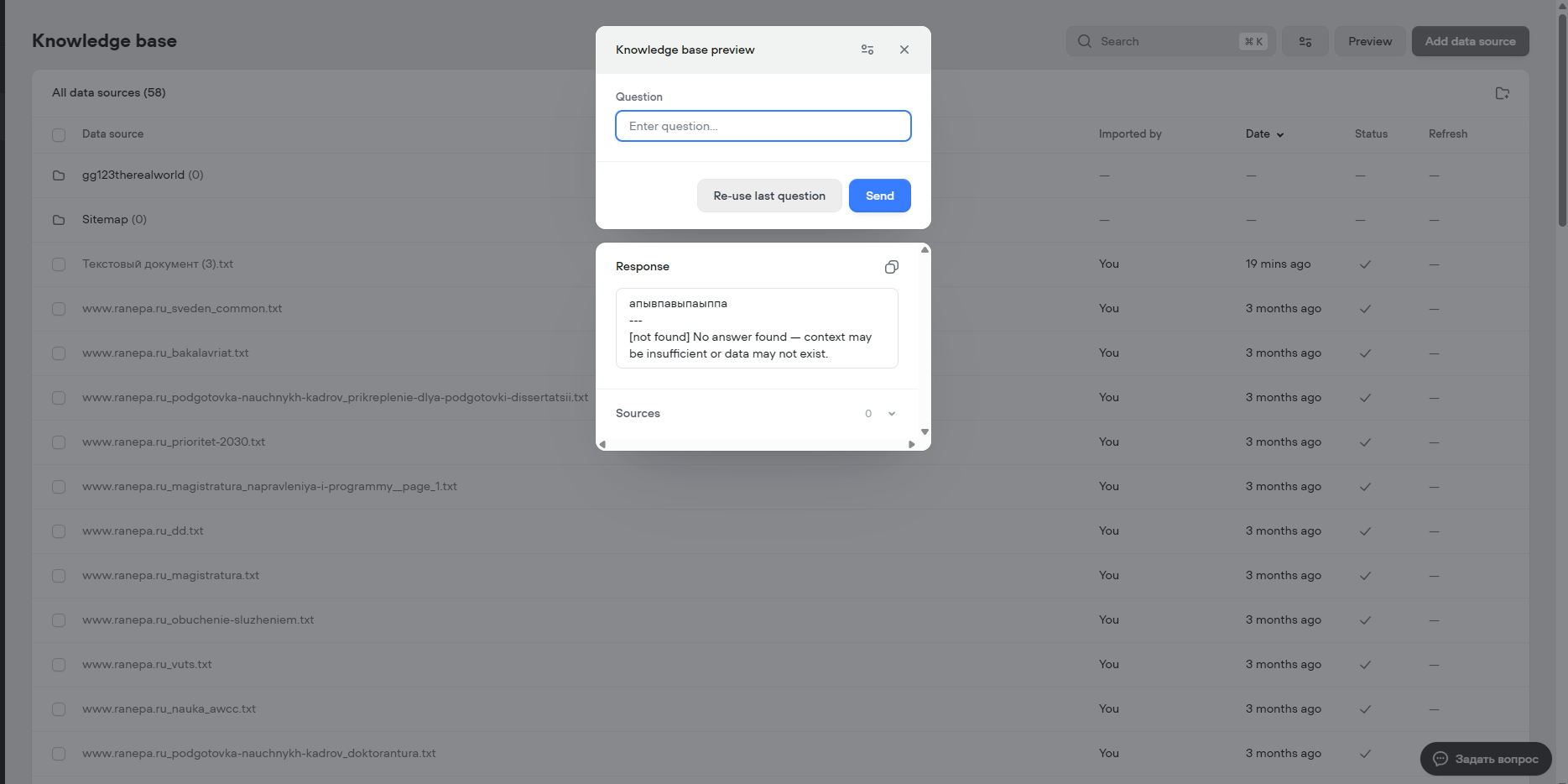
When I delete the only URL, it does not find any chunks at all when searching by the rest of the data.
For clarity, I created another project with the same knowledge base and there the same query, consisting of a set of letters, gives 15-30% relevance, not 80+.
Because of this error, my knowledge base search cannot find normal chunks to answer the question, everything broke for me because of this.
I had the same problem 4 months ago in another project. Then the knowledge base only had URLs, and each search also gave 80+ relevance. Changing the model, resetting the settings and changing the model prompt did not help me. The only thing that helped me was resynchronizing all the data with the YURL.
But in this project I can't do that, because I mostly have files, not links. And it's very strange that this is happening, I would like you to pay attention, since you apparently don't know about it.
KB search behaves the same way.
I would not want to go and delete my entire knowledge base and add it again now, I'm sure that this problem will also happen in the future, it would be better if you fixed it, or told me what the problem is and how I can solve it in the best way.

Exclusive community for Voiceflow Solutions Providers & Content Creators.
13,076Members
Resources
Recent Announcements
Similar Threads
Was this page helpful?

